AI’s favorite coding language is also the most expensive
I ran the same agentic coding task 19 times across three languages. Ruby won on efficiency & speed. Python flunked big time.


Trying my own rage bait
About 3 months ago I posted a study on LinkedIn that suggested Ruby is a strong language choice for agentic coding, which got more than a few accusations of being “rage bait”.
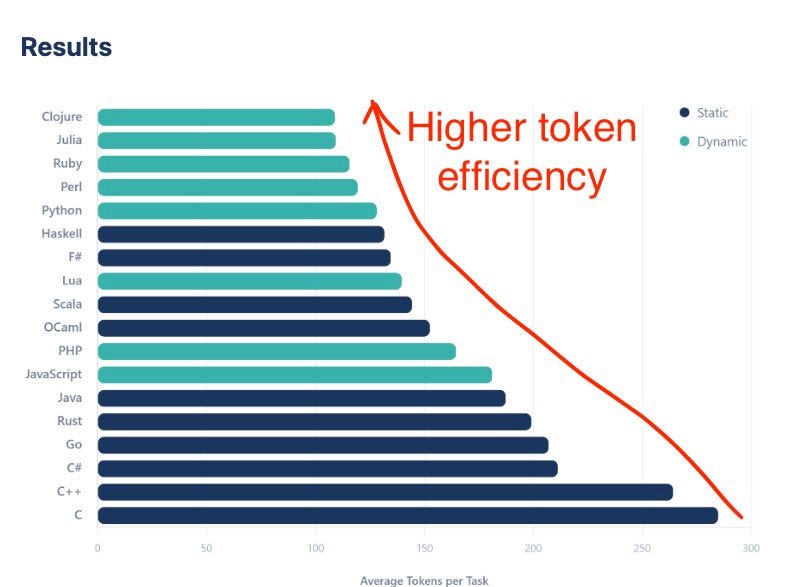
In my last post, I doubled down on the claim that AI agentic coding performs better — faster, fewer tokens — with Ruby than TypeScript and Python, the two other languages Coolhand Labs maintains packages for.
Recently, I found an opportunity to quantify and test that observation. I needed to add the same, relatively straightforward, feature across all three client packages. Seemed like a great opportunity to give my own rage bait a try.
For each package I used Claude Code + Sonnet 4.6 to:
Plan a solution to the GitHub issue
Approve the plan (no revisions)
Have a separate agent perform code review (Opus 4.7 for this step)
Create a PR
Keep fixing test and lint failures until the PR CI was green
Here are the results1:
Maybe not just rage bait after all? As you can see:
Ruby is generally faster & more token efficient
TypeScript is a close second, and its results may be a victim of one really bad run
Python totally flunked the test… until I made some changes
But what surprised me is just how much slower Python is. I ended up running a lot more Python sessions to understand why. The answer says something interesting about both Python, your AI, and the state of agentic coding in general.
Finally, Ruby is fast at something!
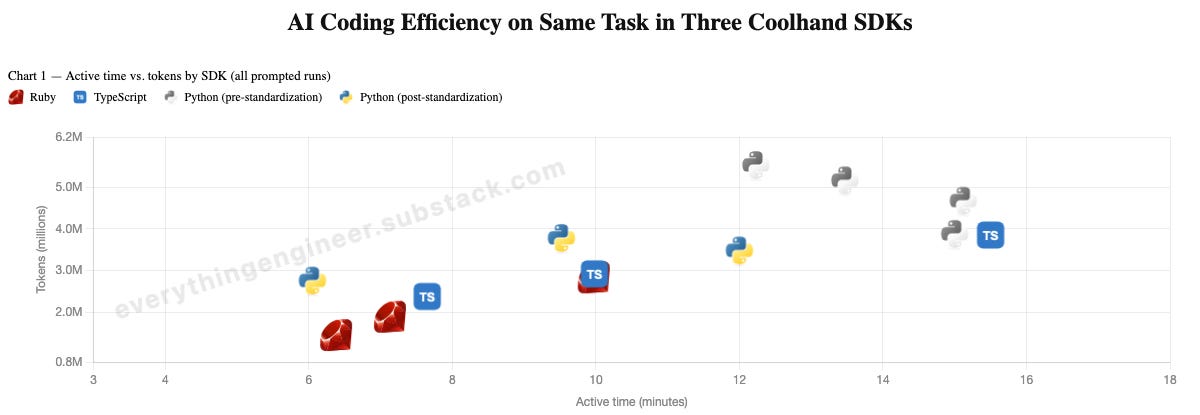
My first run of the same feature across all three repos had an asymmetry I didn’t notice at first: my Python repo was already set up with a custom instruction to always run lint and tests before finishing — Ruby and TypeScript weren’t:

This instruction is useful, so I added it to all three repos and ran again. With a level playing field, the ordering flipped:

One thing I noticed in those Python runs was that it was generating far more linting and testing tool calls than the other two. I had Python running flake8, black, and pytest as three separate verification steps. Reading around pointed me to ruff as a faster, consolidated alternative. That should close the gap, right?
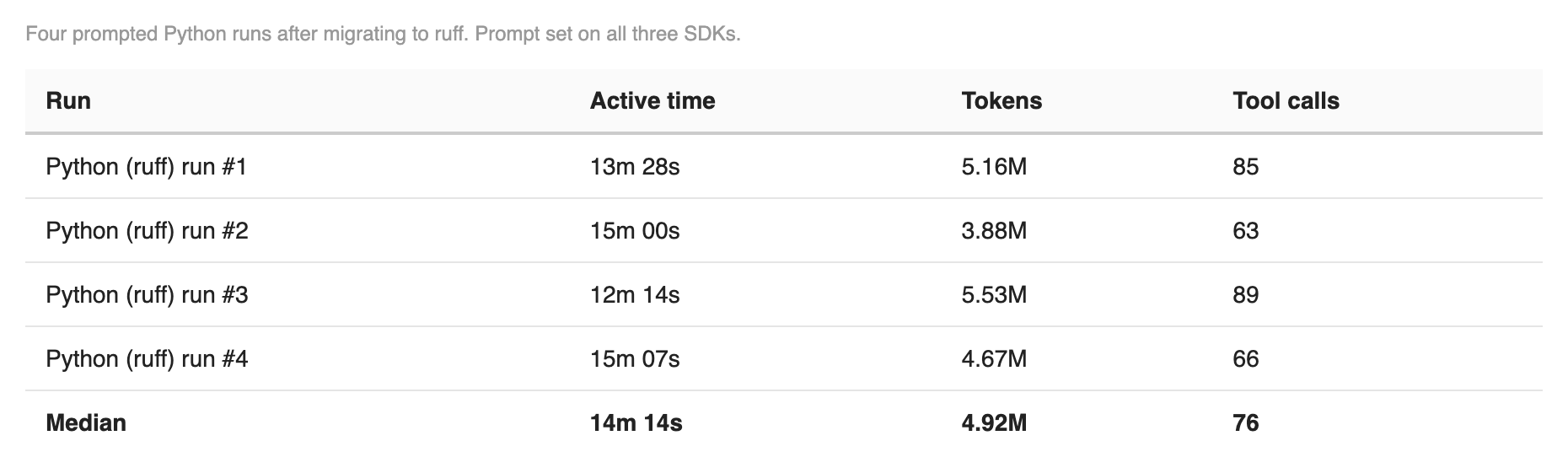
Ruff did what it was supposed to — lint/test rounds per session dropped from 3–5 down to 2. But Python’s median token cost barely moved, and actually crept slightly higher.
What was actually going on?
LLMs are just as bad at setting up Python as everybody else
There’s a famous xkcd comic about Python environments:

Your LLM knows this pain well.
A typical Python session looked like this:
Claude:
make verifyhit a pytest collection error, Claude:
pythonfailed:
python3.12failed:
/usr/local/bin/python3.12failed: .
venv/bin/python
… and on and on, with lots of cat pyproject.toml, cat .venv/pyvenv.cfg, ls ~/.pyenv/versions/ thrown in.
Honestly, it would be easy to make fun of Claude for flailing around like this, but untangling the complexities of the Python env is something a typical human engineer does. Even experienced Python devs — especially experienced Python devs — all have burned endless time on Python configuration hell.
What’s really interesting is that with LLMs we can now quantify, in token counts, how much Python configuration hell costs. Python sessions before I standardized the toolchain averaged about 25 bash invocations per session; Ruby averaged 17, TypeScript 15. Most of the delta wasn’t extra pytest runs or ruff checks — it was the interpreter resolution loop, repeated uv sync calls re-resolving the environment, and explicit env-debug commands that showed up in nearly every session.
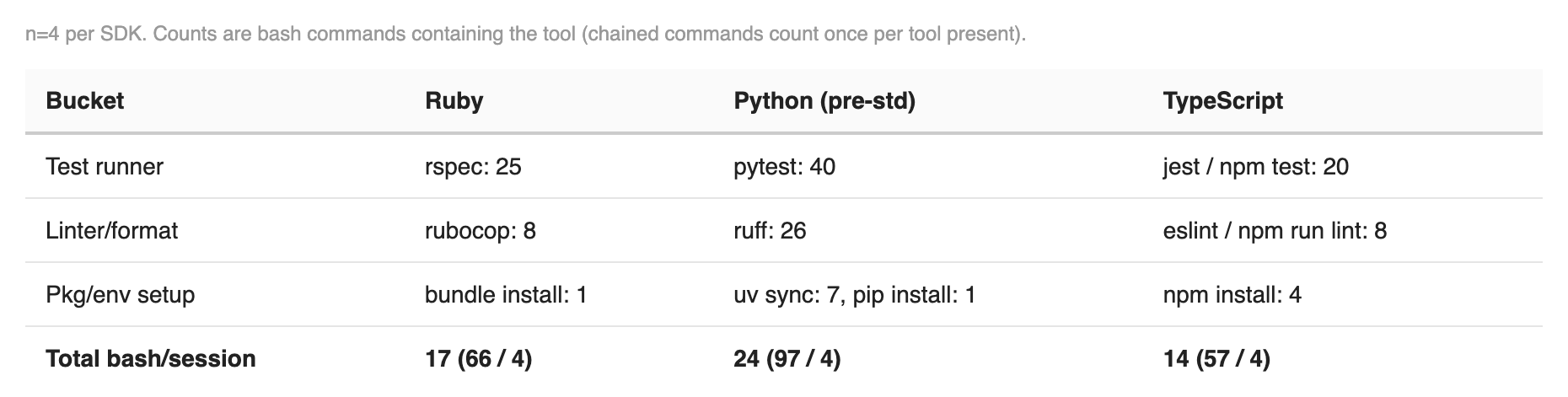
Standardizing your environment yields big results
After four Python ruff sessions running a median of 14 minutes 18 seconds and 4.9M tokens, I shipped a standardization PR: a canonical make verify target that runs ruff and pytest in one call, a pinned .python-version file (should have had that in the first place), and a committed uv.lock. Then ran again.
The first post-standardization session came in at 9 minutes 31 seconds and 3.78M tokens. A 33% drop in active time and 23% fewer tokens versus the prior median!
Python session token cost across all configurations
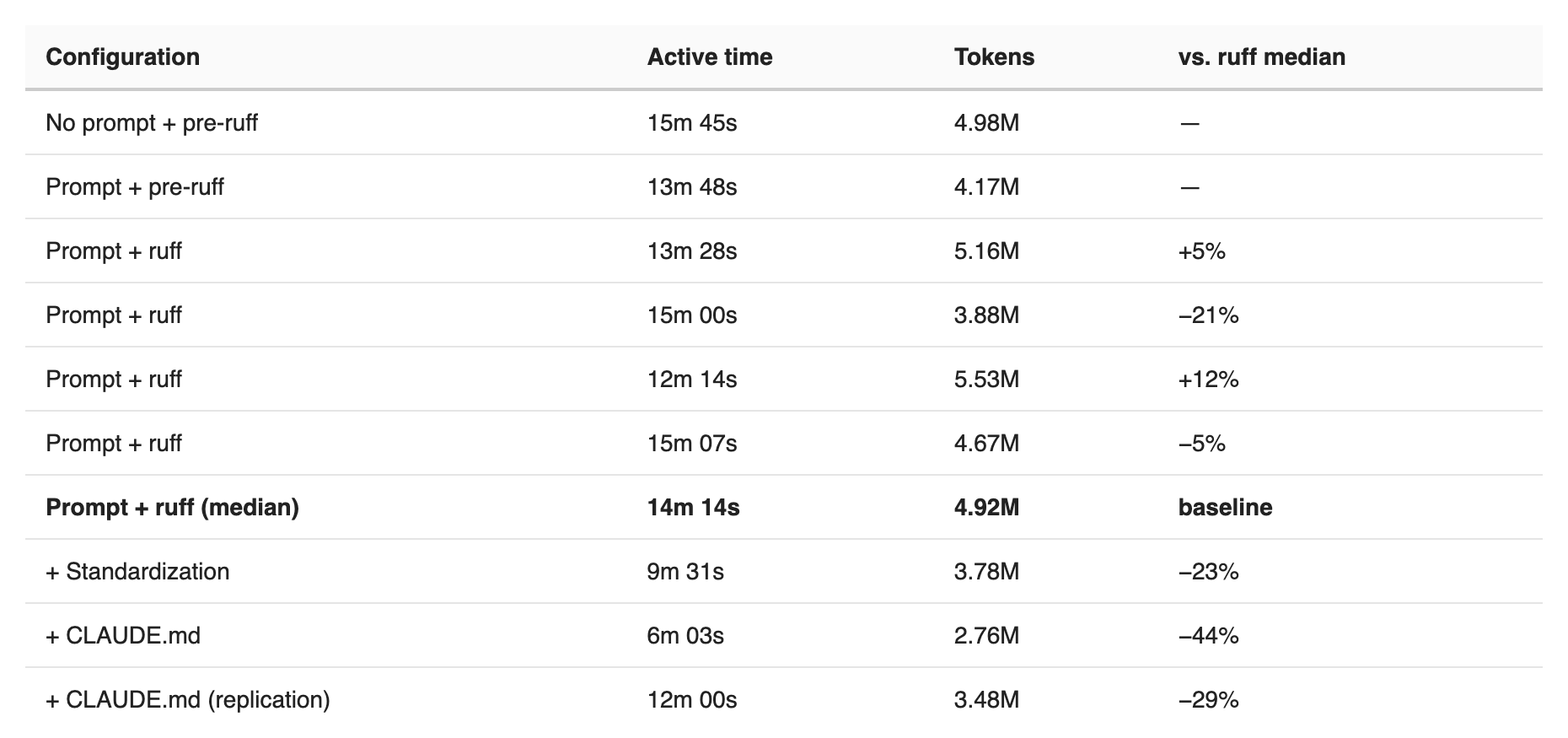
But the session showed the AI was still flailing. Claude used make verify three times, hit a pytest collection failure, and then unrolled into ad-hoc debugging anyway: uv run pytest --version, .venv/bin/pytest -x -q, uv sync --all-extras. The canonical command influenced the start of the session; it didn’t prevent fallback behavior when something actually broke.
So I updated the CLAUDE.md to explicitly require Claude use uv sync --all-extras & make verify and forbid direct invocations of other tools. The first run under this configuration came in at 6 minutes 3 seconds and 2.76M tokens: faster than Ruby’s median time! But the second run with the same config was closer in token cost to the first standardization run.
Claude was doing better with Python, but still reverted to old habits occasionally and was slower compared to Ruby.
Ruby is more efficient, but Python won anyway
I’m not going to conclude by gloating that Ruby won this contest on speed & token efficiency… or at least I won’t any more than I have.
Instead, I want to end with this screenshot, taken from the Claude Code session where I was analyzing all the data:

Yes: even in a session where Claude is meta-analyzing itself and its poor performance with Python, it kept using Python (and not the standardized env I had set up 🤦🏻♂️) to do scripting tasks that any language could perform. It’s not just anecdotal: A study found LLMs are strongly biased toward Python — even on high-performance tasks where Python isn't the right tool, they still chose it 58% of the time (and across the models tested, Rust wasn't picked once… ouch).
Two thoughts from all of this:
If you didn’t care what kind of tools your AI was using before, it’s time to start. The economics of tokens is slowly, but surely, moving in the direction of each unnecessary tool call getting more and more expensive. (Along these lines, there are some band-aids that can help out-of-the-box, like RTK.)
Your LLM needs a complaint box. One big surprise from this experiment, as Claude was thrashing around trying to figure out which Python to use in the same session, it never once complained. It just kept struggling and eating tokens until it got it right. It didn’t have a way to complain… or at least not one I was listening to. I ended up fixing this, but that’s for a future post.
And, of course, review & standardize your Python environment. Python is everywhere, and it’s wired into how models think about scripting and automation. It’s not going away. So give your Python setup some love. A pinned interpreter, a committed lockfile, a make verify target, and a CLAUDE.md that points the agent at it and forbids it from going anywhere else won’t work 100% of the time, but will generally save you tokens.
Your LLM will thank you. So will your API bill.
Michael Carroll is the founder of Coolhand Labs, which helps engineering teams improve AI coding outputs using human feedback. He has now run the same feature implementation nineteen times across three codebases and is still not sure which one is his favorite (definitely not the Python ones).
Caveat upfront: run-to-run variance is large — sometimes 2× on active time within identical inputs. These numbers are directional, not definitive.